
Software architecture. Besides being one of my favourite aspects in the industry, it’s a topic that seems to keep evolving in both importance and the knowledge surrounding it. As a disclaimer, this is my take on software architecture in a modern, ever evolving and chaotic world. It’s based on several years of experience and a personal hunt for the optimal architecture, hence containing a lot of “I think…”.
This post is a 2-part series, with this being part 1. It will reflect on software architecture with a theoretical- and business-oriented mindset and highlight some of the architectural values that I find especially important. Part 2 will have a practical take on those values and a complete demo project including source code available on Github.
Many definitions exist on what software architecture is. Selecting one over others is no fun, especially when this is the perfect opportunity for me to expose my own (biased) definition.
A series of design- and technical choices, which shapes the system and its ability to support ongoing development and daily operation, such that both negative/positive properties of the system are minimized/maximized in a balanced way.
Which is a vague definition compared to others, but don’t worry. Now’s the time to explain and concretize. First it's important to get a grasp on what’s important for the system by defining a series of architectural properties followed by splitting up the architecture into areas of responsibility.
Trying to define the important values of modern software architecture without context is a (NP-)hard problem. This leads to the need of initially defining the context and its properties. I’ve defined 3 ownership groups, each containing a short list of important properties.
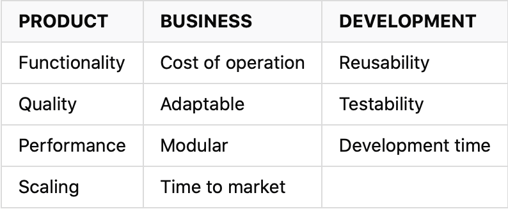
These definitions can be applied across multiple architectural levels based on the given level of detail, from a general system overview to concrete features and how they’re integrated. While a technical document may be non-existing (like most documentation in the world of software), keeping these properties in mind during the process of defining and developing the tasks, they can elevate the final product and reduce future risks and issues.
In a naive world, software architecture can be divided into two groups, each with their own responsibilities – micro and macro. The infrastructure, supporting CI/CD and selected technologies lay the foundation of the system. The point of the macro group in software architecture is to enable developers and business operations to perform better and faster while minimizing obstacles. The micro group of software architecture then reflects on the concrete implementation of features in the system – it’s code, logical structure and the patterns used.

PRODUCT
From a user’s point of view, functionality, quality and (at some level) performance is what defines the product and how satisfied the user is. It’s important for keeping user retention and the business case of the system. Selecting the right front-end technologies and frameworks can position the development of the system to more easily accomplish these properties.
Scaling can be a harder property to nail since it’s usually followed by negative side effects regarding cost, complexity and development time. The easiest answer is to simply not deal with it and not do early optimizations, unless it’s needed or expected to be needed soon. However, this doesn’t mean one should neglect the aspect of scaling.
Many cloud providers today enable customers to automatically scale ressources up/down. Besides the obvious benefits of being able to scale up, scaling down based on load can be an effective cost-reducing tool for the business. However, while scaling is related to system load in which the infrastructure plays an important role, the available scaling options is usually dependent on how the system is built. Things such as preserving the user session over multiple requests can affect this – which in general can be shortened to state vs stateless systems.
BUSINESS
Cost of operations. Urgh – even though building systems is fun, the business aspects are a vital part of the system. A system without a viable business case (negative revenue/ROI) usually result in the system being decommissioned over time. This is not a sob story though. We as developers can do much to improve the viability of the business case simply by understanding that systems cost money. Optimizing bad performing code (CPU time), selecting cost-optimized infrastructure and implementing methods for adaptive scaling is just a few strategies to reduce cost of the system. In hindsight, these optimizations may increase the available budget and by that increase flexibility and the potential to invest in new features. It’s unfortunately not a topic that’s talked a lot about but if Feature A increases revenue by 50 and optimizing existing infrastructure/application performance reduces cost of operation by 100, the business case is strong for the latter.
Adaptability and modularity. One may think that this is a developer thing and has nothing to do with the business. However, if the business requirements never change, the need for adaptability and modularity usually following a similar pattern of not being needed. In a worst-case scenario, a high level of inflexibility of the system may result in new requirements and features being postponed or denied.
Ever heard about that bug? The users became annoyed. The bug resulted in data errors which later would require additional time to fix. Good thing all it took was 1 hour to fi… wait 3 months till next planned release? Time to market is usually a combination of two things – automated builds and release systems (CI/CD) and an optimized process where incremental improvements weights higher than a fictive release number. It may initially be scary to release often if one is not used to it, but if the infrastructure can handle short TTM, so can potential bugfixes and since each release is incremental, the changes in each update is easier to test and verify beforehand. If not for TTM improvements, then the usage of CI/CD internally for improving system development by automation and integration with source control usually affects code quality in a positive way.
DEVELOPMENT
Reusability not only reduces the amount of code needed to complete features, but it also reuses existing components that has already been tested. It’s a win. You want to know what’s not a win? Fixing an issue 3 different places in code, all with similar logic, but forgetting the fourth.
One of my favourite things to focus on early, is how to reduce development time. This is especially true, if the architectural optimizations have no negative consequences on other aspects of the architecture. Two of the common pitfalls that affects development time across all skill levels is startup time to debug and complex code increasing development time in general – that’s why we should refactor code.
An example of a time-reducing strategy is hot reloading. Being able to make changes to the code without restarting the system is infinitely time reducing. A feature could be that the system is able to generate PDF files. Creating the template can be time consuming while nailing the UI. If the templates are loaded from an external source (file on disk), it can at debug time be read every time the PDF is generated hence removing the need to restart the system. At production time, the template can be cached.
And when we are talking about reducing development time, then how about completely removing the need to start up the application to debug? Testability of the written code gives not just the ability to run isolated tests against logic, but also secures that the same methods stays functional over time. Writing tests is like if technical description and continuous integration had a child. The child is well-behaved unless you mess with its methods such that the tests fails. If so, it will annoy you until you either fixed the bug you introduced or update the technical description (the tests). That’s of course only if the code is written to be testable to begin with.
What’s next and the chosen tech stack
Part 2 in this series will have a practical take on software architecture based on several of the defined architectural properties from this post. The system being built is a blog platform with public “walls” and posts backed by a CMS requiring user authentication. Some of the primary properties the system tries to fulfill is related to testability, modularity and minimizing development time.
The tech stack for the system will depend primarily on the following technologies
- Angular 9
- .NET Core 3.1 (ASPNET)
- Mediator + CQRS



