
Not only platforms and frameworks change over time. The application may be separated into multiple sub-applications (microservices) or have parts of its logic shared with other applications.
Defining and integrating architectural values can help keep the system stand the test of time. This post will focus on the values testability, modularity, development time. In addition to this, the overall goal is a way to enforce input validation and authorization of the executed logic, without relying on platform/framework features. The more declarative, transparent and easy to implement these steps are, the better.
The software pattern mediator has a lot to say in designing the solution for this case. The gist of it is, that it encapsulates logic and decreases coupling inside the system. A side effect is, that it enables us to build a request pipeline, which can process the request and perform several checks, before calling the actual logic. One downside is discoverability of request classes compared to a service classes. Shout-out to the library MediatR for a great implementation.
The pipeline
The model validation and authorization checks could be a part of the method's initial statements. However, it decreases transparency of the method, when what we're actually interested in, is a way to perform pre-flight checks before lift-off.
As inspiration, we can look at how ASPNET handle its request pipeline in a simplified manner. The pipeline itself consist of ordered middlewares. Each request received calls the initial middleware after which it traverses through the registered stack of middlewares. For each middleware, it has the ability to modify the context, return a response or call the next middleware in line.
The idea is to build a logical pipeline when executing code/requests, where each part makes sure that the request continues to be valid and can be performed. The pipeline implementations for Ramble is ValidationPipeline and AuthorizationPipeline.
The integration
When a solution grows in size and large projects gets divided into multiple sub-projects, it can get hard to keep track on the dependencies and what each of them require to operate. With improvements to .NET's Host-concepts and how well-integrated DI has become, it's a natural step to utilize some of these concepts to simplify registration, even outside the usual applications like ASPNET.
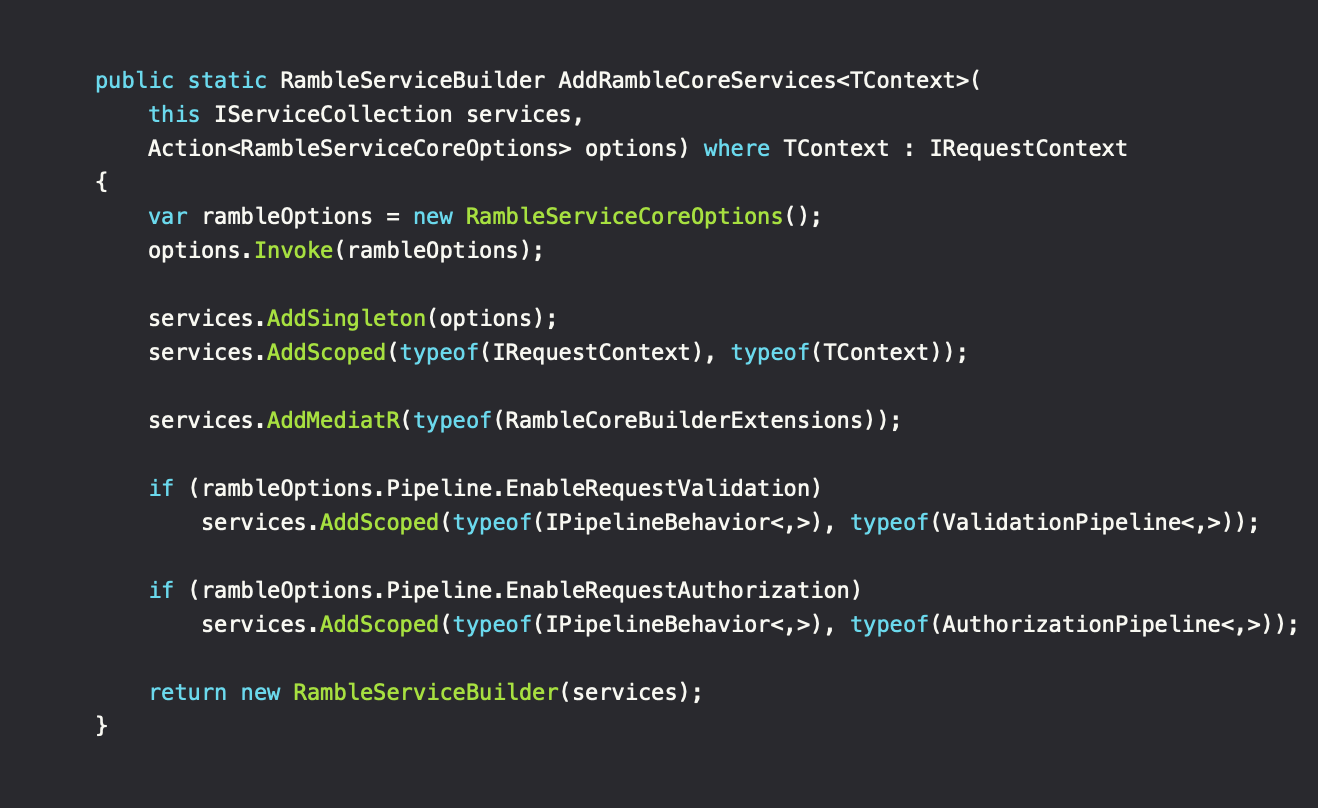
The RambleServiceBuilder gives us our own extension point to simplify discoverability between projects. The AddRambleCoreServices method sets up the pipeline, including any other needed services for that specific layer. Other projects, while referencing our pipeline defining project, can then continue to add service registrations using this builder. An example on this is the AddStandaloneFeature() extension method from the separate project.
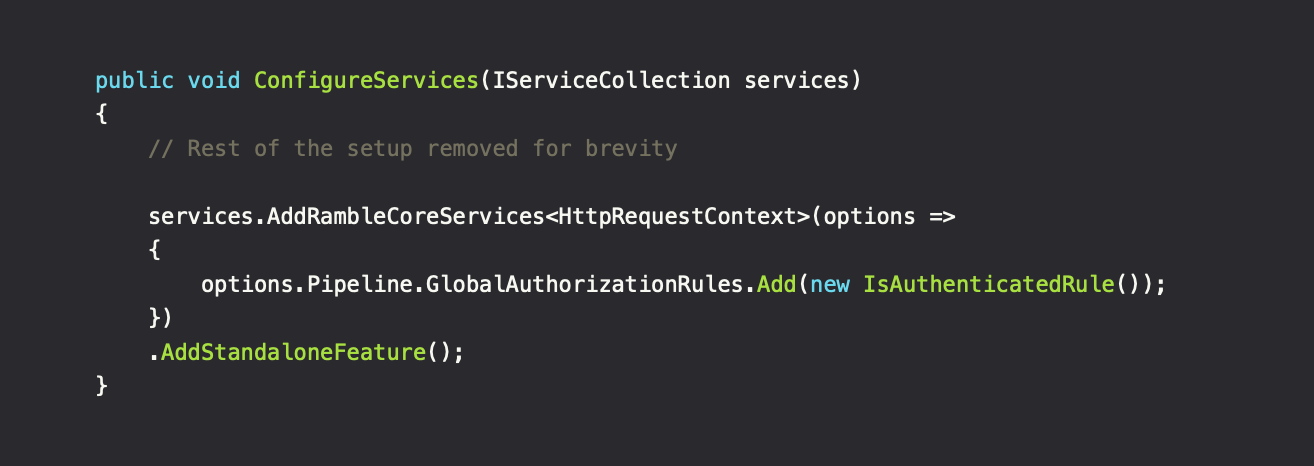
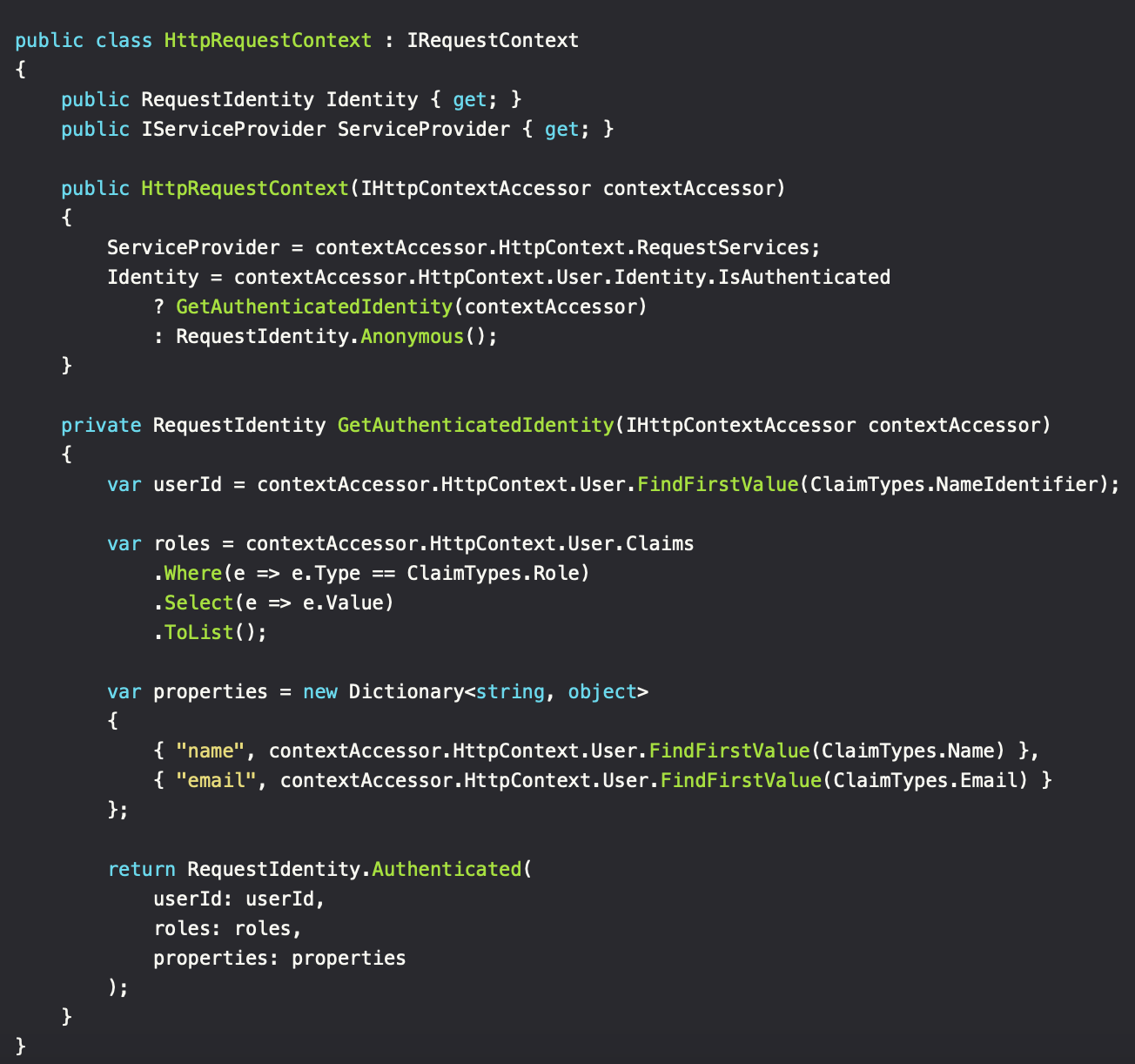
The IRequestContext is a per-application implementation. It defines how the application can construct the request context, which contains a reference to the IServiceProvider and the RequestIdentity. The RequestIdentity instance can be seen as an alias for the current authenticated user. If it's an ASPNET application, it's usually going to be constructed via IHttpContextAccessor. CLI and other application types may have other ways of defining the context. Besides, the goal was to reduce coupling with platforms/frameworks. This means that utilizing IHttpContextAccessor via DI inside the requests, will limit the code to environments where the instance is available (ASPNET).
In action
Defining a request
The request class defines the method signature with its properties as arguments. To extend the behavior of the request, the Validator and Authorizer sub-classes define requirements in a declarative, without cluttering the actual business logic (deleting the wall). Such separation simplifies development, since authorization rules can be shared between multiple requests. Each step (validation, authorization and method execution)can be tested individually, making the testing process more focused and easier to write and validate.
As a side-note to the request and its authorizer. Some authorization checks can't be declared solely on its own, since it plays a central part in the business logic. An example on this is, if we wanted to get a list of all posts, but we only had access to see text entries, not images. This would require filtering of the result, which could be implemented as a post-processing action of the logic. However, I think that in most (all) cases, this adds unneeded overhead and complexity, including the possibility to degrade system performance (fetching all entries, then filtering locally).

Validation and Authorization
To add validation and/or authorization checks, a class inheriting from RequestValidator or RequestAuthorizer can be created. Both classes share the same declarative way of defining the rules via the constructor.
Behind the scene, the validator uses the library FluentValidation. Works great and can handle advanced cases where DataAnnotation attributes fall short.
Regarding the authorizer, the implementation can be divided into rule arguments (the instance added in the Authorizer class) and rule engines, which contains the authorization logic. Mediator pattern to the rescue, since we need to add rules without complex constructors, while keeping the ability to transform a Request object to the given Rule for that sweet reusability value. The engine itself is then created when needed and includes the needed DI capabilities - neat.
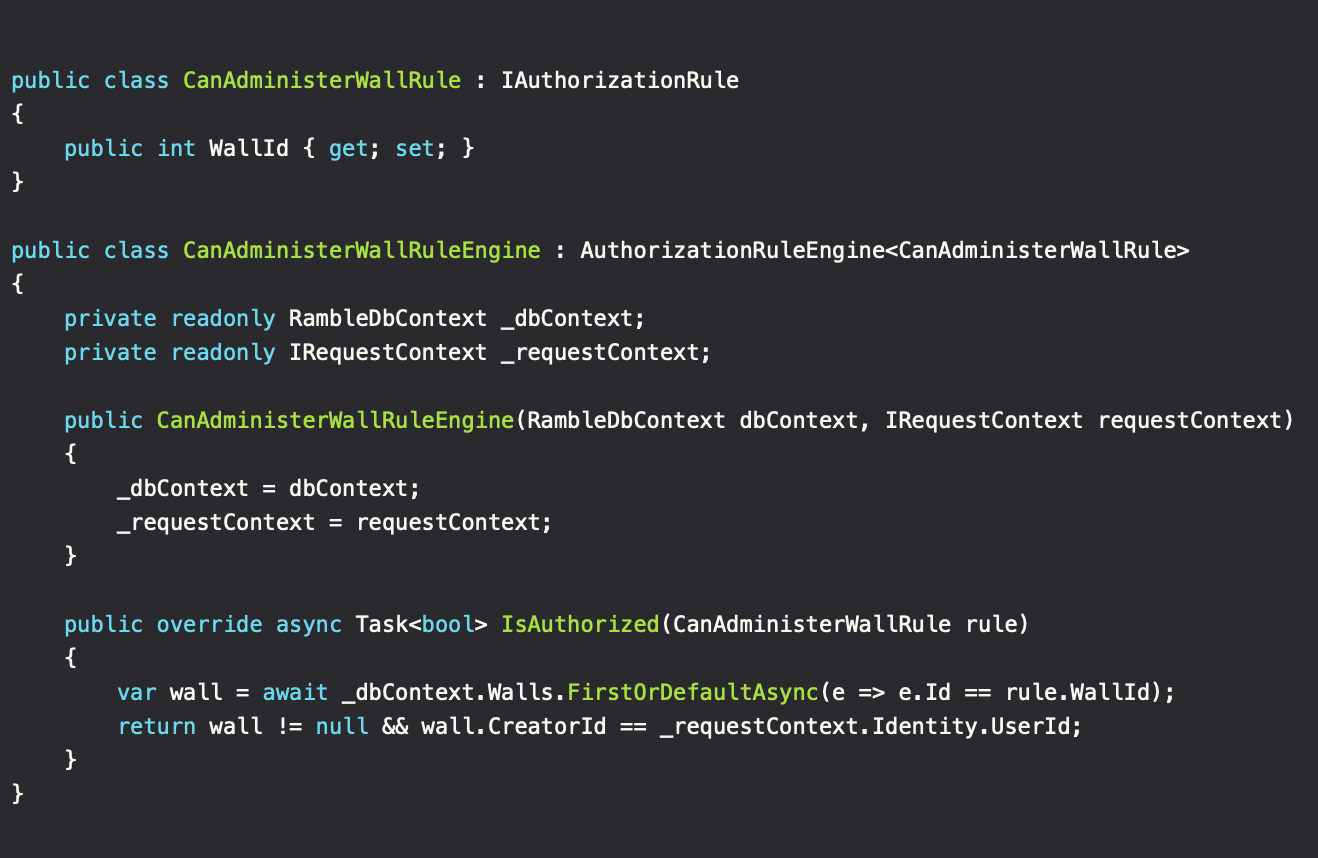
Request logic
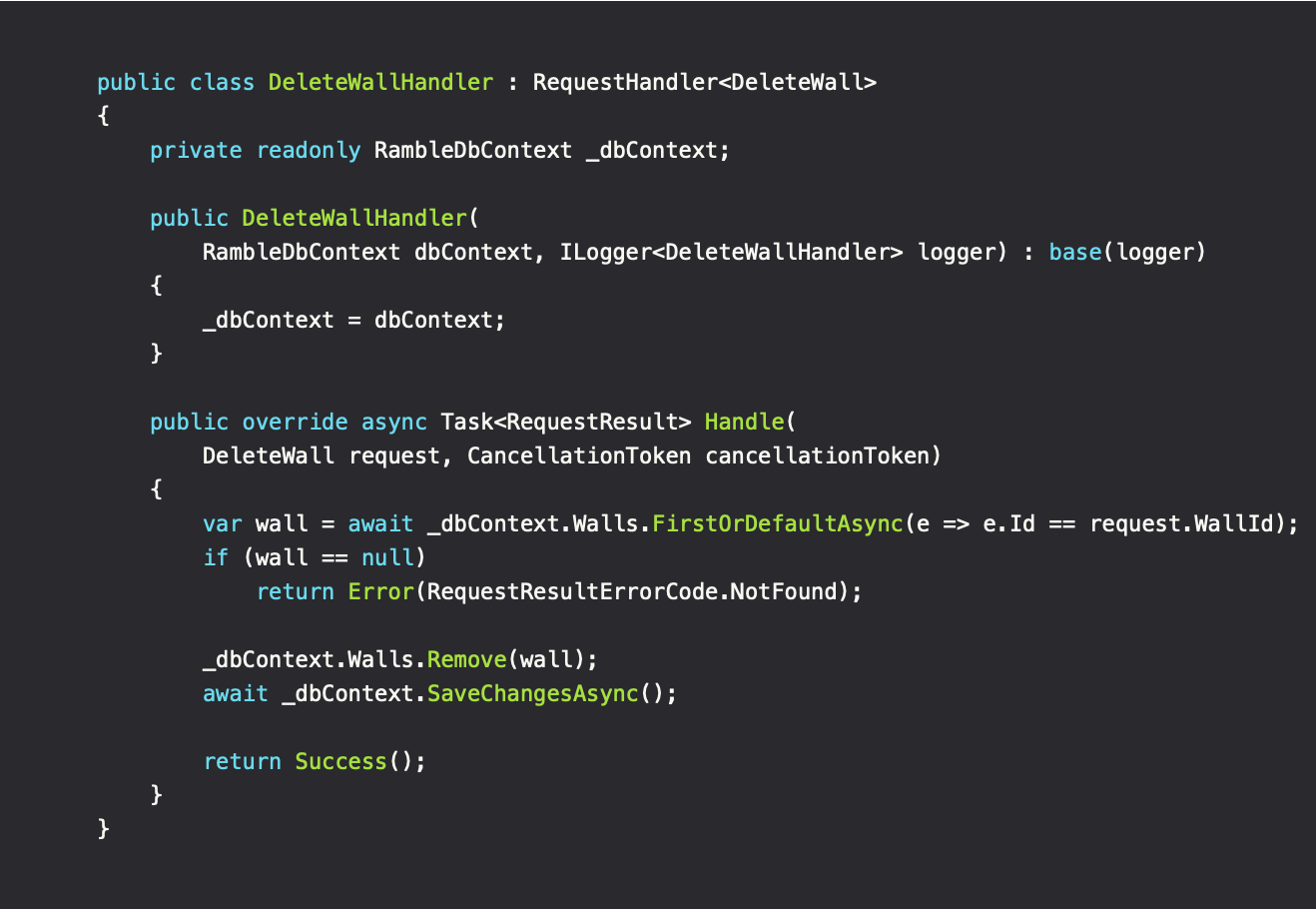
When the request has been created and the validation/authorization steps passed, the time for executing the actual request logic begins. Since this part has been guarded before being executed, we know that the request is valid and the identity executing it is authorized. This simplifies our code as seen below. In addition to this, since each RequestHandler is based on its own class, we can DI only what's needed. Compared to traditional service classes, which needs to DI everything needed to construct the instance at once, regardless of what the called method(s) needs. This helps to increase transparency of the code.
It may initially seem like we're hitting the DB twice, both times asking for the same object. However, Entity Framework caches the Wall entity with the initial request, after which it is fetched locally for the proceeding requests. This is due to the context having a scoped lifetime in our DI container and its query tracking behavior enabled, which is on by default.
The application interface
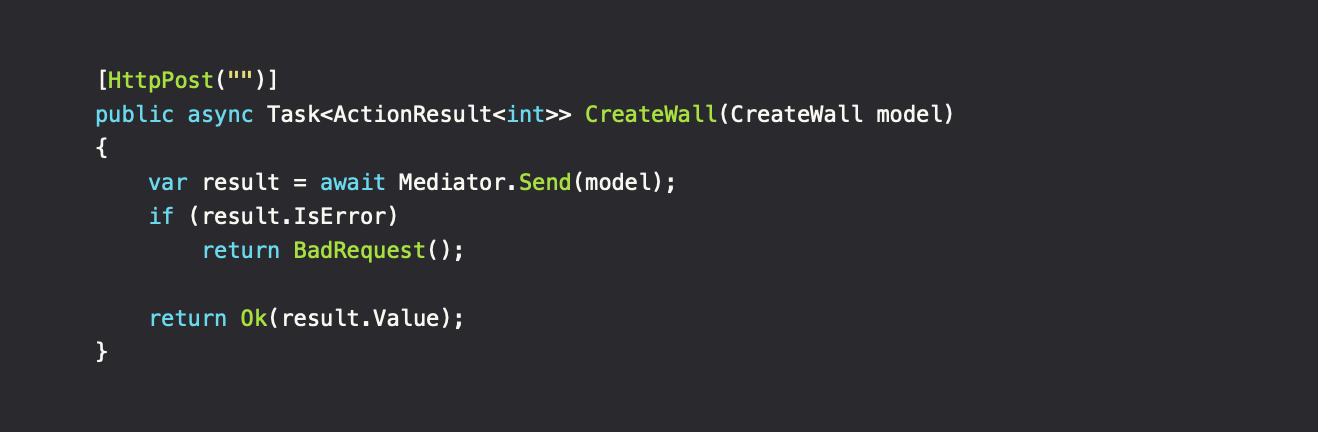
With everything in place, the pipeline is ready to be used. In this case, we have an ASPNET API controller which handles the creation of walls.
The controller knows the interface/protocol between the application and the user, not our pipeline. By that definition, it's the applications responsibility to create the correct form of response to return to the user. The result from our pipeline is wrapped in a Result object which, besides the result itself, contains basic information regarding the state. Do consider using a DTO instead of the Request class directly as API argument to separate concerns.
Testability
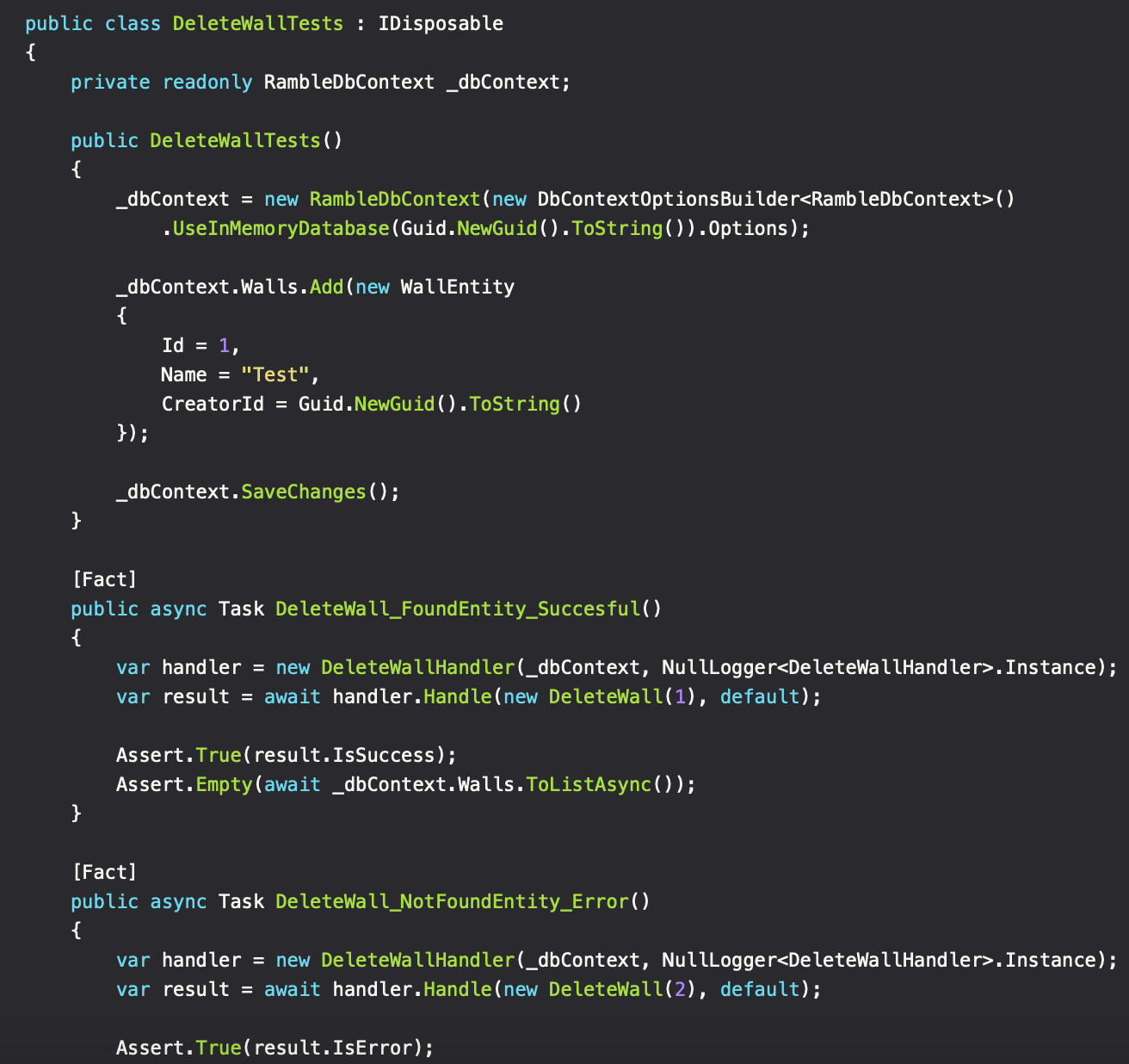
So how does this hold up regarding testability? First of all, the separation of authorization and request logic simplifies writing the tests and makes it easier to accommodate the possible outcomes of the code being tested.
When an authorization rule has been created and tested, it can safely be used for other requests when needed. No need to test for those outcomes again.
 To see the full code snippet visit: https://dev.to/itminds/from-service-classes-to-request-pipelines-9eg
To see the full code snippet visit: https://dev.to/itminds/from-service-classes-to-request-pipelines-9eg 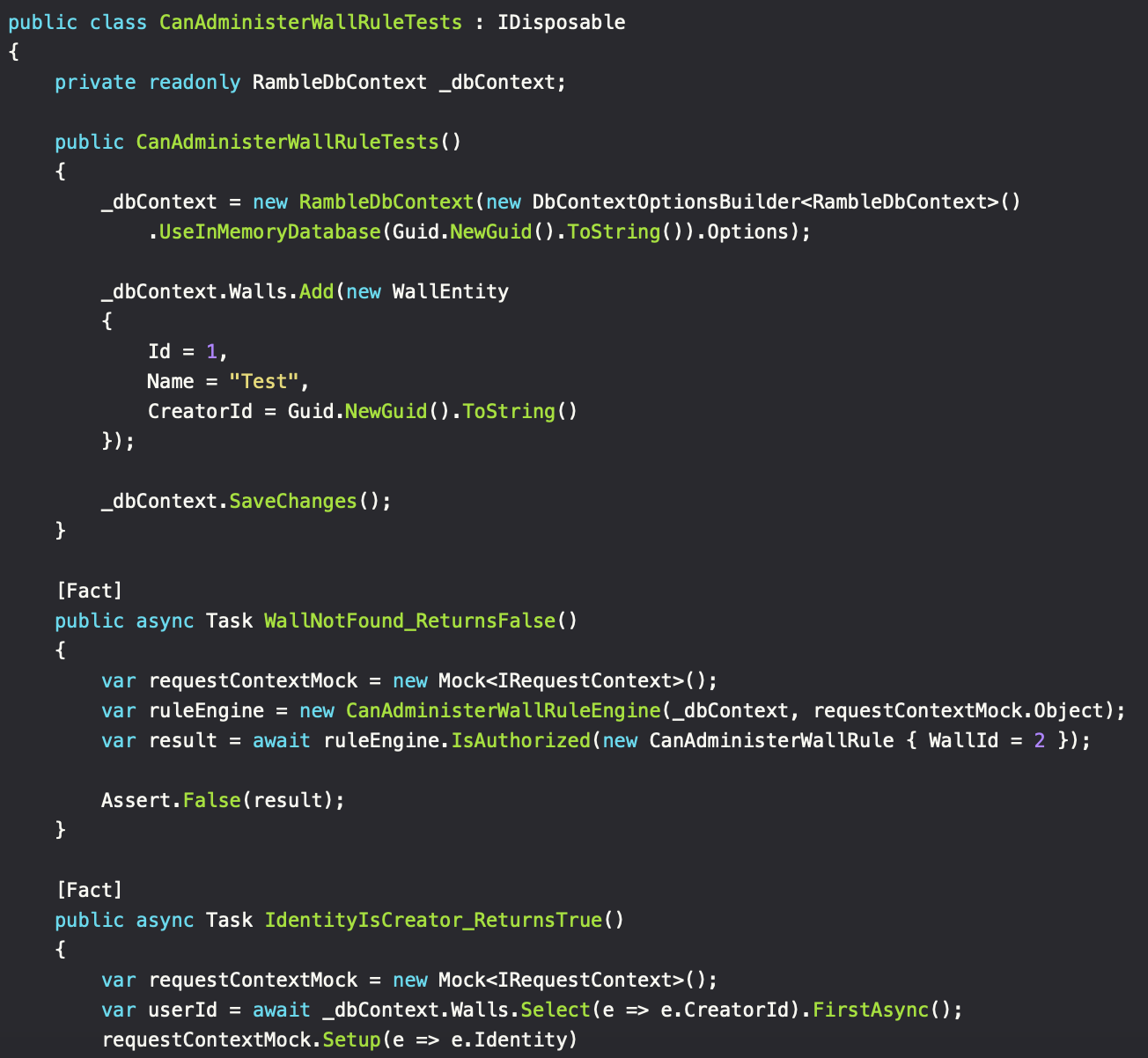
Source code
Interested to see more? Ramble is a personal, public faced project of mine, used to experiment and validate my thoughts related to software (and architecture), in the land of .NET and Angular. In the end, the successful parts get introduced/integrated in real world-projects.



